|
EDR610
: The Class
: Good Measurement
: Part 1
: Lesson6-1-1
|
|||||||
| Validity & Reliability (Part I)
Greetings, Research Fans! In Module 6, we'll be looking at "two key properties of good measurement." These are qualities that we need to be aware of when we design measurement procedures for collecting data on our variables of interest: be they quantitative or qualitative written surveys, standardized test scores, interview protocols/guides (lists of planned questions), and so forth.
These are so essential, and yet sad to say, they tend also to be neglected, overlooked and/or "misassessed" in actual research studies. In fact, according to several prominent research authorities, the Number One reason for rejection of research papers (by journals, professional conferences, and so forth) is failure to do an adequate job in this area! These two key qualities of good measurement are known as "validity" and "reliability." KEY QUALITIES (PROPERTIES) OF "GOOD MEASUREMENT" I. Validity - Basically, this means, "Are we measuring what we think we are?" It is the issue of credibility or believability of our measurement.
One of my former doctoral students told a wonderful story about this that, I think, really drives home the point! (Thank you, Tess! As I told you would happen: you're now "immortalized" in my lectures & presentations!!): You see a familiar-looking creature waddling across the street ... hmmmm, it's a bit far away (and/or you happen to be a bit nearsighted), but here's what you can manage to make out: it's got feathers and wings; it's got webbed feet; also, a beak; and it's waddling. Sooooo ... based on these observable 'clues,' you conclude: "It's a duck!" EXCEPT ... it suddenly gets a little closer (or, if you're like me, you are persuaded to ditch your 'vanity' and FINALLY put on your glasses!), and you suddenly realize, "Hey, that beak is wider than what I initially thought: by golly, it's NOT a duck, but a platypus!!" So now, therefore, let us pause for the following brief commercial announcement ...
 That's the kind of "well-intended mistake" that CAN be made with regard to validity! You take your best shot from the observable clues and hope that 'reality' (or in a research sense, what you're measuring) is 'what you think it is' from the clues! As with Type I error in statistics, there's always some chance you might be wrong -- but you can build a more or less convincing case with stronger evidence of 'validity:' more to come on that one, shortly! The reason why it's a problem or issue with measurement is this: more often than not, when we measure or collect data in research, our key variables of interest are actually UNOBSERVABLE (or, more accurately, NOT DIRECTLY OBSERVABLE) CONSTRUCTS. These might include: Our "challenge" in measurement, if you will, is to collect data, or evidence, on "GOOD-ENOUGH OBSERVABLE MANIFESTATIONS" of these unobservable constructs! And if/when we can do so, we have "evidence" as to what the value of the "not-DIRECTLY-observable" constructs. As in a courtroom case: no one REALLY knows the "true" state of "guilt" or "innocence" except the "accused" (who might have selfish interests to want to lie!) and the "victim" (who might be dead ...!). BUT -- the mandate of the jury is to make a decision as to the state of this "not directly observable" construct of "guilt or innocence" by carefully weighing any existing evidence, the arguments presented by the attorneys, the testimony of subpoenaed witnesses, and so on and so forth -- and reach some sort of determination as to the "value" of this "construct" from such observable evidence. And ... depending on the "strength"/credibility of such evidence, you can feel "more" or "less" confident about the "value" that you conclude for the construct (of "guilt or innocence"). So, too, is it with validity! It is NOT, as some researchers have naively assumed, an "all-or-nothing" proposition! Rather, it is more like a "continuous variable"(ah, shades of Lesson Packet # 1 in statistics!). That is, one can make a "less" or "more" convincing case that one's measurement and assessment procedures are "valid!" Let's look at one more example of what we mean by "not-directly-observable" constructs and using evidence from "observable manifestations" or "measurements" to reach conclusions about what must be true about such constructs. Specifically, let's look at the highly relevant (for us!) but not directly observable, "academic achivement."
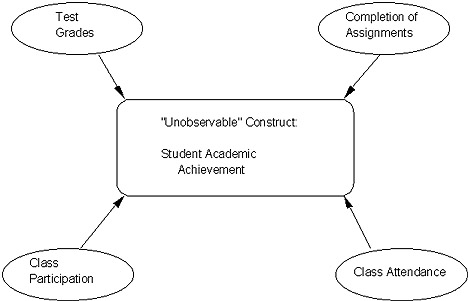 We gather our "clues" as to the "level" of a student's "academic achievement" (the not-directly-observable construct of primary interest) from multiple observable "manifestations" or actual "measurements/data." These might include, for instance, his/her: 1) test grades; 2) track record for completing assignments; 3) in-class participation; and 4) overall attendance. The more independent "pieces" of such evidence we have, of course, the "more confident" we are that our "judgment call" regarding academic achivement is "credible" (valid). And, of course, the more closely these different pieces of evidence agree, the more confident we are, as well. We might assume, then, that a student who: 1) has consistently high test grades; 2) always turns in his/her homework on time; 3) always eagerly raises his/her hand and participates in class discussions; and 4) has perfect (or near-so) attendance would be "high" in academic achievement. And, we could easily assume the converse, as well. But ... just as with Type I error, we could be wrong! For instance, even with "agreement" of low test scores, late or missing assignments, poor participation and poor attendance, there is certainly at least one "competing" ("iceberg variable") explanation: illness! It would certainly "account for" all of the preceding, regardless of the student's level of academic achievement! This, then, is the "validity" challenge: how sure can we be that we are measuring what we think we are? And that it's not being confounded or contaminated by something else?! Open the link below and go through all of the pages of this courtroom metaphor which explains how the legal system is a good metaphor for how the collection and weighing of evidence in research in order to reach a conclusion (e.g., verdict). II. Reliability - Basically, this means, "Are we measuring consistently, stably, or predictably?"
Now, given that a bathroom scale measures "weight," it IS measuring what it's supposed to (valid). But here's how it can be QUITE UNRELIABLE ... We know we can certainly fluctuate in weight. BUT, I think you'd have a hard time believing in the "credibility" of your bathroom scale if you get on it and it tells you, say, "120 lbs." and then 5 minutes later you get on it and it tells you "150 lbs.!" That would be a most unreliable measuring instrument! Another real-life example that makes the same point, and which is often used, is that of the "rubber yardstick." If you accidentally pull on it and stretch it, it is not measuring inches, feet, height, or whatever, consistently/stably/predictiably or 'reliably.' Basically, that unit of measurement is not constant due to the 'stretching!' (or broken springs on the bathroom scale). There are basically 2 types of 'stability' or 'consistency' that we can think about: 1) across raters (judges); and 2) across time. The first is very commonly applied. Here is what the interrater reliability issue looks like:
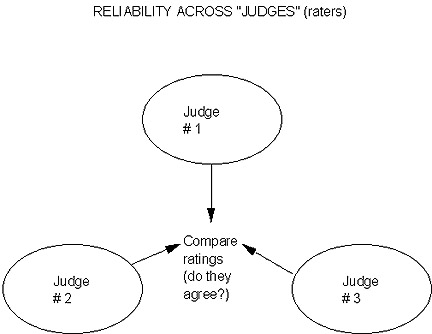 Although I've illustrated 3 "raters" or "judges" in the preceding diagram, there could be any number. We allow, of course, for some "slight" individual variation -- but even so, we have more confidence in the consistency or stability of the measuring instrument/procedure if the different judges tend to "converge" in their individual scores or ratings. How I hesitate to use the following example, only because it's potentially sooooo sexist ... but it DOES make the point ... ! So please know that no gender bias whatsoever is intended -- only an object lesson ... ! When I think of interrater (or judge) reliability, I think of the typical beauty pageant (e.g., Miss America, Miss Universe, and so forth). If there is "good" or "high" interrater reliability, even with slight variation, a given contestant will get, say, scores of # 1, # 1 and # 2 from the 3 judges. But the other extreme -- an example of "poor" interrater reliability -- would be # 1, # 50, # 36! If/when something like that happens, it would make you want to question or re-examine the scoring criteria (e.g., the "measurement procedure" in this case: how the judges have been instructed to rate, what to look for, and so forth). Are they too vague? inconsistent? leave room for hidden contaminant biases? etc.? OK -- 'nuff said! Hope that made the point of "good" vs. "poor" interrater reliability!!! And now for our 2nd type of "assessment of consistency" -- across time:
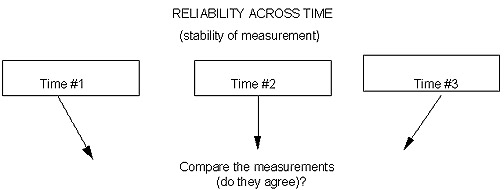 Now, we do need to be a bit "realistically careful" with this one. After all many things can, and would, be expected to change over time! Not only physiological properties like weight, blood pressure, blood glucose levels (sorry; being a diabetic I tend to focus on 'that which I know ... !'), as well as those intangibles (learning; motivation; self esteem; academic achievement). But, the question again becomes: what is reasonable? both in terms of the magnitude of change and the related time period. We can agree, I'm sure, that a 30-lb. weight change within 5 minutes would not be reasonable -- therefore it was the 'measuring stick' (bathroom scale) which had to be off. Similarly, and we'll return to this example in Research Lesson Packet # 10, even with individual variation, a 4th-grade child's I.Q. test score wouldn't be expected to change by 50 points within a one-week time span -- something had to be "off" in terms of the administration/scoring of that test. This, then, is the issue of "stability across time" and potential "clues" (if the magnitudes are 'off') as to some error, inconsistency, instability, or unreliability of the associated measurement procedure. One final issue for your consideration in this lesson packet: How do these two key properties of "good measurement" go together? More specifically, can a measurement instrument (procedure) be reliable but not valid? Oh, yes! It could consistently (reliable) be "off its intended mark (invalid)!" Let's look at an example of a "bull's-eye type target" and two patterns of "shots:"
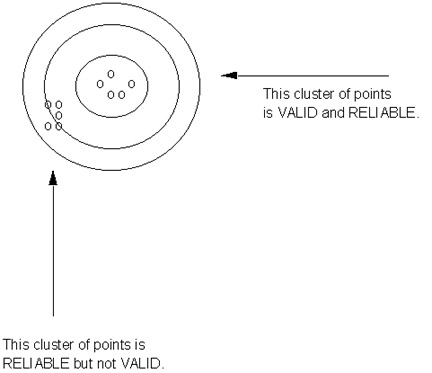 * The cluster of "shots" in the center or "bull's-eye" would be considered BOTH reliable(even within slight variation, they are consistent -- e.g., they 'cluster together') AND valid(hit the center, again with slight variation). * The second set of "shots" certainly is equally consistent or reliable (they, too, tend to "cluster together"). However, notice that they are considerably "off the mark" and therefore invalid. Here's where we're headed! In Topic 2, we'll look at four ways (actually, sort of 4 1/2!) to assess validity; And we'll wrap things up in Topic 3 with four ways to assess reliability! Talk about ending on a "valuable note ... !" 
Once you have completed this assignment, you should: Go on to Assignment 1: Mission (NOT) Impossible E-mail M. Dereshiwsky
at statcatmd@aol.com
Copyright 1998
Northern Arizona University |

