 |
Electronic Textbook:
Survey Research - Part II
"Ask and Ye Shall Receive:" Survey Research: Part Two: Selected Response
and Response Choices
What
is a Survey? American Statistical Association
We're in the middle of our 'survey trilogy,' research cyberfans! This time
out, we'll take a look at some alternative types of SELECTED RESPONSE
or FORCED- CHOICE questions. (For a more general discussion of how
these differ from the other, open-ended type, please see the previous chapter,
Survey Research, Part One. Also, if any of you would like copies of the
related interviewing material from our qualitative modem course, and you
don't already have it ... well, our current title says it all! "Ask
and ye shall receive!")
These examples are from a rather unique book entitled, Scale Development:
Theory and Applications by Robert F. DeVellis. It was published in
1991 by Sage Publications, Inc., of Thousand Oaks, CA and is #26 in Sage's
excellent Applied Social Research Methods Series. The reason I refer to
this book as "unique" is that it combines discussion of two related points
that are seldom presented jointly. The book starts with a rather rigorous,
comprehensive discussion of issues of validity and reliability of measurement
procedures. Then the second half is taken up with survey development,
design and refinement. I think it is commendable for DeVellis to "so suitably
set the stage," couching survey item construction in the larger, more
important, holistic issue of "what are we measuring? how dependably? how
credibly?" It is tempting to 'tinker in isolation' with survey items and
sometimes lose track of the 'bigger picture' of validity and reliability.
(And by the way, we'll talk about pilot testing, cover letters, etc.,
next time around in our next topic)
Ready? Let's take the scenic view...!!!

I. Likert Scales
Let's start with this one, especially since it's one of the most
popular forced-choice item formats! It's widely used in educational
survey research, particularly in measuring attitudes, beliefs
and opinions.
The basic idea here is to:
- write the item as a declarative sentence and;
- then provide a number of response options, or choices, that would
indicate varying degrees of agreement with, or endorsement of, that
sentence.
Let's take a look now at a couple of examples:
Figure 1.
Examples of Likert-Scaled Survey Items

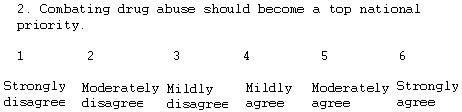
Please note, in the above two examples, that the "item" to be evaluated
consists of a declarative sentence. Thus, it already states
a 'position' and 'direction' of attitude. The respondent is then
asked to circle the direction and extent (intensity) of
his/her agreement (or disagreement) with that "position" sentence.
Occasionally, I'll see subjects construct the Likert scale items as
questions: e.g., "Should combating drug abuse become a top national
priority?" and then list the same choices. But - you can't really
"agree" or "disagree" with a question! since it is in open-ended
form! In order to gauge direction and intensity of agreement/disagreement,
the subjects have to have 'something definite to react to;' i.e., a
declarative sentence such as the two examples, above.
The next question that invariably arises is: how many response choices
should be included? Related to this point is the sub-question: should
there be a middle, neutral, or 'balancing' point?
- Usually 5 or 6 choices are the most commonly found!
- There are, unfortunately, no hard-and-fast rules about whether
there "should" be an "odd" vs. "even" number of choices. The decision
depends largely on what is being investigated, as well as extent of
prior work in this area (what have other similar surveys measuring
this phenomenon looked like? if there were Likert scaled items, how
many choices were there?) This is but one of many issues that can
be pretested and shared with a sample of pilot judges, as we'll see
next time around.
- About the only "catch-all" rule of thumb is that, despite the ordinal
nature of the response data (a blast from the past, Intro to Statistics
fans! Remember scales of measure in our Module # 1?!), you should
try to construct the response choices so as to have "roughly equal
intervals with respect to agreement," according to DeVellis. We
can see this in the 6 response choices for our 2 Likert examples above.
The choices look about evenly spaced: strongly-moderately-mildly on
both the agree and disagree sides.
Now -- back to the "odd" vs. "even" issue for a moment, as per #2 above.
Having an "ODD number" of choices invariably leads us into the thorny
issue of "should there be a middle point? and if so, what should
be its exact meaning and nature?"
Let's tackle those in reverse order! and start with some "popular,"
plausible choices for how to label that middle point (response choice
on our Likert scale), if we do choose to have one!
Such mid-point labels might include:
- Neutral;
- Neither agree nor disagree;
- Agree and disagree equally.
Question of semantics! Some would argue that the above labels are equivalent!
However, DeVellis and others make a case that there could be a subtle
but definite distinction in some readers' minds, particularly between
b and c. According to DeVellis, "The first (b) implies apathetic disinterest,
while the latter suggests strong but equal attraction to both agreement
and disagreement." (pg. 69) He does have a point! I would put it this
way: c (equally) appears to suggest 'active brainpower and thinking
about it on the part of the subject,' while b (neither) might be chosen
'on a whim' by a subject who does not want to think deeply about the
issue(s) at hand!
Now -- back to the 'stickier wicket' of whether there ought to even
be a 'middle point' to begin with! As you've probably guessed, perhaps
the main issue here is: "Is providing that middle point allowing
for subjects to 'cop out?'when in fact we as researchers really
need to know the direction and intensity of their attitudes?!"
This issue has troubled researchers, so much so that a large number
of 'simulation studies' have been done. The results with and without
a middle point have been compared to try and gauge its impact.
In general, two conclusions can be reached:
- As many as 20% of subjects will tend to choose the middle category
when it is offered - although it has been found that these
subjects would not volunteer it if it weren't mentioned; however,
- At the same time, this has at most a limited effect on the distribution
of responses in the other categories (e.g., the ratios of those
who would choose, say, "mildly" to "moderately" agree or disagree).
Let's look at the results of a simulation done by Schuman and Presser
in 1981. They wrote the same question both ways, with and without the
middle point. The relative response distributions (percentages) were as
follows:
|
Should divorce in this
country be easier or more
difficult to obtain than
it is now?
|
Should divorce in this
country be easier to
obtain more difficult
to obtain, or stay as
it is now? |
Easier 28.9
More difficult 44.5
Stay as is
(volunteered) 21.7
Don't know 4.9 |
Easier 22.7
More difficult 32.7
Stay as is 40.2
Don't know 4.3 |
From Converse and Presser (1986)
While the size of the middle category differs in the two alternative
formats, Converse and Presser point out that the ratio of "easier"
to "more difficult" is about the same. That is: not counting the middle
and don't know responses, this ratio ("easier" to "more difficult")
is about 40:60.
As Converse and Presser have concluded, "Offering a middle position
makes less difference to individuals who feel strongly about an issue
than it does to those who do not feel strongly." (pg. 37)
In our earlier discussion, we learned that Likert scaled items should
consist of declarative sentences - ones that "take a stand," thereby
giving the subjects "something to react to," i.e., agree or disagree
with. A related question then arises: how "strong" should that statement
be?
One might, for instance, classify the following Likert scale items
as follows:
| Wording |
"Strength" of Statement |
| "Physicians generally ignore what patients say." |
Strong |
| "Sometimes, physicians do not pay as much attention
as they should to patients' comments." |
Moderate |
| "Once in a while, physicians might forget or miss
something that a patient has told them." |
Weak |
Here is the tradeoff, as DeVellis and other survey experts see it:
- With "too mild" a statement, there might be too much "yea-saying,"
surface agreement with that statement. Then, about the only thing
you get is "bandwagoning" - but not a true gauge or differentiation
of subjects' attitudes. Also, if such statements are "too mild,"
they run the risk of essentially washing out any attitude or
opinion - being totally neutral in tone.
- On the other hand, too strong a statement runs the risk
of offending, shocking or otherwise upsetting the subjects.
The experts advise that it's better to err in the direction of
"too STRONG" than "too MILD." The best solution would be
to help ensure - again, perhaps with explicit input from a pilot test
panel - that your statements state directions and intensity of
attitudes in clear, unambiguous terms.
Please click below for more information on Likert Scaling.
Likert Scales
II. Semantic Differential Scales
These center around a stimulus. This could be a person, thing,
event, position, or whatever focused variable choose.
For the semantic differential you would:
- Identify the stimulus;
- Under it, list several pairs of adjectives.These would
be written at opposite ends of a horizontal line - thereby representing
the polar ends of a continuum.
- Subjects would then mark the line on each continuum that best
depicts their opinion regarding this stimulus.
Let's now look at a specific example:
Figure 2.
Example of a Semantic Differential Scale

In the above example, automobile salespersons
would be the target stimulus - the "thing" being evaluated
according to the pairs of adjectives representing continuua of opinions.
In reality, there would be more than two (2) such pairs of adjectives
presented with the stimulus; the above is but an abbreviated example.
With regard to the question of how many response choices,
or dashed lines on the continuum between the two pairs of adjectives:
again, there are no hard and fast rules. Most often, in actual surveys
one sees between 7 and 9 choices.
There are two ways to develop the adjective pairs:
- a) bipolar adjectives: these express the presence of
opposite attributes; e.g., "friendly/hostile."
- b) unipolar adjectives: these would indicate the presence
or absence of a single attribute; e.g., "friendly/not friendly."
As an endnote comment, you will sometimes see these referred to as
"Osgood's Semantic Differential," since they originated with
the seminal work of Osgood, Tannenbaum and other researchers in the
1950's.
III. Thurstone Scaling
For this type of survey item, your goal is to formulate a series
of sequential statements about some target attribute. You would
attempt to 'space' or scale those statements such that they they
represent equal intervals of increasing or decreasing intensity
of the attribute.
Subjects would only be given TWO CHOICES for each statement: "agree"
and "disagree." The researcher then looks at which items 'triggered'
agreement. Due to the equal interval desired phrasing of the original
items, it is then hoped that the agreements reveal "how much of" that
attribute the respondent has, or agrees with. This, then, would make
the scores "behave" like interval data.
Again, an actual example
might help clarify the above ideas! It's contained in Figure 3, below:
Figure 3.
An Example of a Thurstone Scale
(target attribute:
"measuring parents' aspirations for their
children's educational & career attainments")

As you can imagine, the process of writing 'successively
equally spaced interval gradations-of-the-attitude' items can be subjective
and tricky! For these reasons of reliability and validity, as
well as other problems arising from their use and application, Thurstone
items should in most cases not be the preferred method of choice.
Please look at the link below for more information on Thurstone Scaling.
Thurstone Scaling
V. Guttman Scales
As you'll see momentarily, these are highly similar
to Thurstone scales. The Guttman scales, however, are
designed to follow even a more closely "ordered, successively higher
levels" of an attribute.
Please look very carefully at the difference in Items
#3 and #4 for the Guttman scale (Figure 4, below), as compared with
Items #3 and #4 for the Thurstone scale (Figure 3, above).
Figure 4.
An Example of a Guttman Scale
(target attribute:
"measuring parents' aspirations for
their children's educational & career attainments")

With the Thurstone scale, there was a 'switch in directionality,'
while with the Guttman there is a progression in the same direction.
Thus, for the Thurstone, we look for the occurrence of a single
affirmative response, while in the Guttman we look for
the point of transition from affirmative to negative responses.
One problem with the Guttman, in addition to the subjectivity
issue raised with the Thurstone, is that it implies if you respond
positively to a given item, you would also be assumed to respond positively
to those items "below it in the hierarchy." Whether or not this 'order
effect' will always be true depends on the phenomenon or attribute
in question. For instance, in Figure 4 (Guttman example), a subject
could conceivably agree with Item #3 but disagree with Item #4. This
could be the case if, for example, the respondent perceived "success"
as a rather complex & multi-faceted variable, one that could possibly
both help and hinder happiness in various ways.
- - -
Please look at the link below for more information on Guttman Scaling.
Guttman Scaling
Now that we've taken a look at the various item formats for such forced-choice,
closed-ended questions, let's end this lesson with a brief discussion
that pertains to most of these. "How many response choices should
I have per question?"
Issues Regarding "Optimal" Number of Response Choices
As indicated earlier, there is simply no 'single magic
number' that represents the best overall total number of response choices.
Instead, I would like to propose some issues or criteria that DeVellis
and other survey researchers suggest be taken into consideration.
I. Variability/Covariability
This may be an important property to "pick up" when you are measuring,
say, an attitude! Without 'enough' choices as to levels or intensity
of, for example, 'agreement' or 'disagreement,' you may only be picking
up a 'rough cut' of a person's true level of attitude. The extreme
would be simply to offer two choices: "agree" or "disagree." This
is a start but does not tell us "how much/to what extent" the subject
agrees or disagrees. With a greater number of choices -- e.g., a 5-point
Likert scale arrayed from "strongly disagree" to "strongly agree"
-- there would be a 'finer partition' of such measurement. This, in
turn, would give the survey researcher more specifically pinpointed
information about the level of the person's attitude.
Even though the above criterion, variability, would imply that "more
choices are preferred to less," this still depends on some other factors.
For one thing: will only a single survey question be asked
that deals with this topic? Or will there be a 'set' or 'range' of
different survey items that try to 'tap' various aspects of the question?
With more discrete items, you are making 'multiple measurements'
and therefore, you can 'get away with' having fewer response choices
per item. On the other hand, with fewer (or, in the extreme, only
a single) item per topic, you may need to offer more response choices
to 'get at' the subject's level of attitude, opinion, etc.
An example might help to clarify this idea. DeVellis offers the following
hypothetical survey scenario. Suppose that the researcher is studying
the enforcement of non-smoking policies in a work setting. Suppose
further that he/she wishes to determine the relationship between such
policies and anger of the employees toward these policies.
Suppose too that the survey is limited to just the following two
questions:
- "How much anger do you feel when you are restricted from smoking?"
for smokers; and
- "How much anger do you feel when you are exposed to others smoking
in the work place?" for non-smokers.
Given the limited number of questions in the first place, the researcher
might obtain more useful and specific information regarding the subjects'
attitudes by allowing for a greater "gradation" or variety of response
levels - e.g., asking them to specify a value on a scale of 0 (not
at all angry) to 100 (very angry).
On the other hand, suppose that the researcher had instead generated
and pilot-tested a total of, say, fifty different Likert-scale items
designed to tap different aspects about both the policies and the
extent of the workers' emotions. These could run the gamut from types
of policies; enforceability; sanctions; awareness of workers; extent
of workers' input into formulating the eventual policies; etc. Given
the larger number and range of items, tapping different facets of
the underlying key variables, perhaps in this case even a simple "agree/disagree"
would suffice. It would still be possible to add up the scores for
the fifty items (say, scaling "disagree" as a 1 and "agree" as a 2)
and create a "summated scale score:" total value for attitude across
the 50 different 'facets' or items regarding attitudes/anger towards
the smoking policies. This would "push" the score in the direction
of "continuous" (many possible values) data - i.e., interval scaled.
Thus, the general "rule," for this criterion, at least, might be:
- Fewer items - > more response choices per item;
- More items - > fewer response choices per item.
II. Subjects' Ability to Discriminate Meaningfully
This one is more of an 'internal, perceptual' issue. How fine
a distinction can subjects make IN THEIR OWN MINDS regarding the level
of their attitude or opinion?
For example, a 50-level scale designed to differentiate and finely
partition extent of agreement or disagreement may be too much for
subjects to handle. But let's 'get real:' how many respondents can
meaningfully distinguish their own levels of an attitude on this
many scale points?! This may be a case of cognitive overload -
and not very representative of how people actually think! Subjects
may actually respond either by guessing (and more on that problem
below) or by mentally rescaling the 50 choices to multiples of 5 or
10 only - in order to make the task more manageable for themselves.
Mathematically, while the variance/covariability may indeed INCREASE
with this many choices (as per the first criterion, page 3), this
may all be 'random noise' or 'error variance' if subjects end
up 'just guessing' at their true level of response with too many choices!
III. Specific Wording and/or Placement of Items
These issues of survey construction may sometimes "spill over" and
directly affect the subjects' ability to discriminate meaningfully
between response choices. Thus, this factor can have an unintended
"interaction effect" with our 2nd, preceding "discriminatory ability"
factor (II, above).
- Terms like "Several" "Few" and "Many" can cause reliability
problems - they are somewhat vague and your definition
of "how many is 'several'" may differ from mine!
- Placement on the page may also subtly influence interpretation.
Consider the array from left to right of the following choices:
Many
Some
Few Very
Few
None
This would 'spatially' lead the subjects to implictly assume
that "few" is more than "some," simply due to the order effect
(e.g., the way the eye naturally moves across the items to process
them). Again, if this is your intent, this would be fine! This
is just intended as a cautionary note as to how physical placement
can affect cognitive interpretation!
- C. Worst case scenario: combining AMBIGUOUS TERMS with AMBIGUOUS
PAGE PLACEMENT!
Consider the following:
Very Helpful
Somewhat helpful |
Not very helpful
Not at all helpful |
First of all, "somewhat" and "not very" are vague and rather confounded
to begin with. But think about the potential for additional interpretive
error introduced by the placement!
- a) If a subject reads down the first column and then down the
2nd, "somewhat" seems like it's a 'higher' value than "not very."
- b) BUT - if a subject instead reads across the first row
and then the 2nd, the exact opposite is implied!
Clearly, lots of room for reliability and validity problems
with the responses!
IV. Researcher's Ability and/or Willingness to Record a "Large Number"
of Values for Each Item
DeVellis uses a 'thermometer' analogy to get us thinking about
this key issue: Exactly how much precision is desirable? do we
need? can we meaningfully process (statistically and otherwise)?
This issue must be thought through in reference to the specific variables
you are trying to measure via the survey questions and related responses.
V. Odd vs. Even Number of Responses/Middle Point
We have already discussed this one under Likert scales, pg. X, along
with the concomitant decision of whether to include a 'middle' or
'balancing point,' as well as 'what its nature should be.'
- - -
I hope that this module has given you an overview of the 'finer points'
of writing closed-ended survey items: the different types, as well as
how many response choices should be provided!
There are a number of outstanding survey construction books on the market.
I'd like to recommend a few of these to you in case you'd like to pursue
additional reading in this important measurement area!
Several summers ago, when I was asked to teach the Survey Design course,
I chose the following two books as our "readers" for the course. Let me
share with you what they are, as well as what I particularly like about
them:
- How to Conduct Surveys: A Step by Step Guide, (http://www.businesssavvy.com/101259n.html)
by Arlene Fink and Jacqueline Kosecoff. 1985: Sage Publications, Inc.
This one continues to win rave reviews from our doctoral colleagues!
For one thing, it is chock-full of lots of practical examples of "how
to take so-so-written survey items of all sorts and rewrite them to
make them better!" In fact, I also 'pulled a fast one' and used this
book in my 'live' EDR 610, Intro to Research, classes. The reason
is that it nicely treats survey construction in the overall perspective
of the entire research process. Thus, you also get good, solid, clearly
written discussion on population and sampling - which makes sense
in terms of WHO will be filling out the surveys! as well as other
aspects of the research process. Thus, I (and our doctoral colleagues,
according to favorable 'word of mouth!') consider this to be a classic
overall research primer, as well as a survey construction and refinement
primer! It is on reserve in Cline Library under: EDR 798, Dissertation
Seminar, Packard - and "much" checked out!
- Survey Research Methods, 2nd ed. by Floyd J. Fowler, Jr.
Volume 1: Applied Social Research Methods Series, 1993, Sage Publications,
Inc. Although a bit 'more advanced' in tone than the Fink & Kosecoff
book, also an incredibly readable, clear book on any/all aspects of
survey construction. Contains a good chart on 'relative tradeoffs'
of telephone vs. mail vs. personal surveys (hint, hint, dissertation
fans: grist for the mill for your Chapter 1 Limitations!). We have
the 1st edition on reserve in Cline Library as well.
- Survey Questions: Handcrafting the Standardized Questionnaire,
by Jean M. Converse and Stanley Presser. No. 63 in the Quantitative
Applications in the Social Sciences series: A Sage University Paper,
1986. A 'condensed, handbook-type' (80-pg. small green paperback)
of the "how to tinker with survey items and rewrite them" that is
also contained in Fink and Kosecoff. Doesn't have the "holistic, surrounding
discussion of other parts of the research process," but for what it
does, it does magnificently! That is: zeroing in on 'tinkering with'
survey items and improving them. I can't recall offhand if this one
is on reserve in Cline or not. I believe the handbooks in this series
cost something like $ 7.50-$ 8.00 apiece (plus shipping) if bought
directly from Sage. Well worth having as a handy reference if you're
planning to go the closed-ended survey question route!
- - -
Questionnaire
Survey Bibliography
Next time, we'll close out our "survey trilogy" by looking at issues
of pilot testing, validity and reliability. For those contemplating
the dissemination of mailed surveys (perhaps the most popular channel
of distribution), we'll also talk about the elements of a 'good' cover
letter to accompany your mailed survey.
Continued wishes for a hefty return rate to all
of our
budding survey researchers ... !!!
Once you have finished you should:
Go on to Assignment
1
or
Go back to Survey
Research Part II: Ask and You Shall Receive: Types of Response
E-mail M. Dereshiwsky at statcatmd@aol.com
Call M. Dereshiwsky at (520) 523-1892

Copyright © 1999 Northern Arizona
University
ALL RIGHTS RESERVED
|