Data-Intensive Computing on Emerging Architectures Framework (DISCOFRAME)
Overview
DISCOFRAME is an NSF-funded project examining the spectrum of hybrid data-intensive algorithms for astroinformatics applications. With the rise of heterogeneous architectures in data centers, leadership class computing facilities and commodity machines, there is a large design space for data-intensive applications that utilize CPUs and GPUs. Algorithms tailored to the strengths of each architecture are required to achieve peak performance. However, given the different models of parallel computation, it is not clear what algorithm design decisions will lead to the best performance. Figure 1 illustrates the continuum between GPU-only algorithms and hybrid approaches. The three broad categories are as follows: (i) GPU-only which are defined as those that minimally involve computation on the host; (ii) task hybrid which are defined as primarily having task parallelism between the CPU and GPU (e.g., a producer-consumer pattern) where the CPU and GPU both have individual tasks, but little attention is given to the utilization of each resource; and (iii) mixed hybrid where the CPU and GPU can have both task and data parallelism, and resource utilization is optimized on each architecture. The latter requires exploiting algorithms specific to the strengths of each architecture. In particular, DISCOFRAME relies on workload characterization, performance modeling and resource optimization to determine the best application configuration on a target platform. To perform these modeling studies, several algorithms from databases, machine learning and data mining are employed. These algorithms will be used in the Solar System Notification and Alert Processing System (SNAPS), which will alert the astronomy community to transient events in the Solar System for the Legacy Survey of Space and Time (LSST).
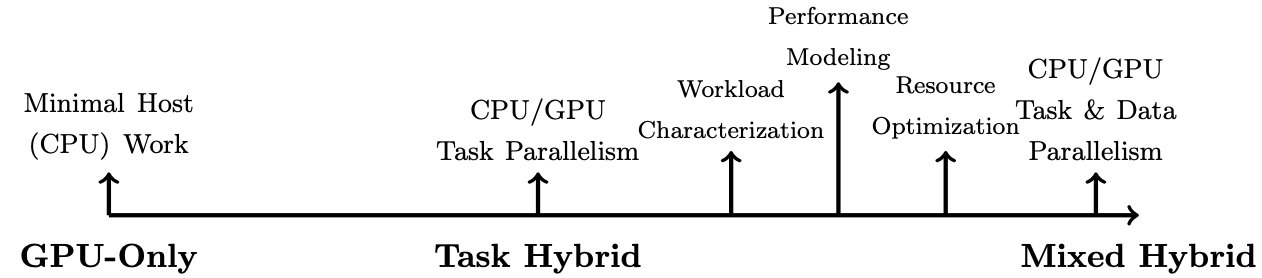 Figure 1: Continuum of GPU algorithms (from only using the GPU to fully exploiting CPU and GPU). The majority of the algorithms are found towards the GPU-only domain.
Figure 1: Continuum of GPU algorithms (from only using the GPU to fully exploiting CPU and GPU). The majority of the algorithms are found towards the GPU-only domain.
NSF Award Information
Broader Impact: Pedagogic Modules
Part of this project includes pedagogic modules for teaching parallel and high performance computing using data-intensive applications. These modules can be integrated into courses at the undergraduate and graduate levels. Website
Publications
- Data-Intensive Computing Modules for Teaching Parallel and Distributed Computing [PDF]
Gowanlock, M., & Gallet, B.
11th NSF/TCPP Workshop on Parallel and Distributed Computing Education
Proceedings of the IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pp. 350–357. DOI: https://doi.org/10.1109/IPDPSW52791.2021.00062 - A Study of Work Distribution and Contention in Database Primitives on Heterogeneous CPU/GPU Architectures [PDF]
Gowanlock, M., Fink, Z., Karsin, B., & Wright, J.
Proceedings of the 36th ACM/SIGAPP Symposium on Applied Computing (SAC ’21), March 22–26, 2021, Virtual Event, Republic of Korea. pp. 311–320. DOI: https://doi.org/10.1145/3412841.3441913 - Hybrid KNN-Join: Parallel Nearest Neighbor Searches Exploiting CPU and GPU Architectural Features [PDF]
Gowanlock, M.
Journal of Parallel and Distributed Computing (JPDC), 149:119–137, 2021, Elsevier. DOI: https://doi.org/10.1016/j.jpdc.2020.11.004 - Heterogeneous CPU-GPU Epsilon Grid Joins: Static and Dynamic Work Partitioning Strategies [PDF]
Gallet, B. & Gowanlock, M.
Data Science & Engineering, Springer. DOI: https://doi.org/10.1007/s41019-020-00145-x - A Coordinate-Oblivious Index for High-Dimensional Distance Similarity Searches on the GPU [PDF]
Donnelly, B., & Gowanlock, M.
Proceedings of the 34th ACM International Conference on Supercomputing (ICS 2020), Barcelona, Spain, Article No. 8, pp 1–12, 2020. DOI: https://doi.org/10.1145/3392717.3392768 - Heterogeneous CPU-GPU Epsilon Grid Joins: Static and Dynamic Work Partitioning Strategies [PDF]
Gallet, B. & Gowanlock, M.
Data Science & Engineering, Springer. DOI: https://doi.org/10.1007/s41019-020-00145-x - Accelerating the Unacceleratable: Hybrid CPU/GPU Algorithms for Memory-Bound Database Primitives [PDF]
Gowanlock, M., Karsin, B., Fink, Z., & Wright, J.
Proceedings of the International Workshop on Data Management on New Hardware co-located with ACM SIGMOD/PODS, Amsterdam, Netherlands, July 1, 2019. Article #7, 11 pgs. DOI: https://dl.acm.org/citation.cfm?id=3329926 - GPU Accelerated Similarity Self-Join for Multi-Dimensional Data [PDF]
Gowanlock, M., & Karsin, B.
Proceedings of the International Workshop on Data Management on New Hardware co-located with ACM SIGMOD/PODS, Amsterdam, Netherlands, July 1, 2019. Article #6, 9 pgs. DOI: https://dl.acm.org/citation.cfm?id=3329785.3329920 - Hybrid CPU/GPU Clustering in Shared Memory on the Billion Point Scale [PDF]
Gowanlock, M.
Proceedings of the ACM International Conference on Supercomputing 2019 (ICS), Phoenix, AZ, USA, pp. 35–45, 2019. DOI: https://dl.acm.org/citation.cfm?id=3330349 - KNN-Joins Using a Hybrid Approach: Exploiting CPU/GPU Workload Characteristics [PDF]
Gowanlock, M.
Proceedings of the 12th Workshop on General Purpose Processing Using GPUs (GPGPU-12) co-located with ACM ASPLOS, Providence, Rhode Island, 2019. pp. 33–42. DOI: https://dl.acm.org/citation.cfm?id=3319417
Code
Most of the code in the publications above is publicly available in the repositories below. The only exceptions are the modeling papers (DaMoN’19 and SAC’21) and the paper on the pedagogic modules in EduPar’21.
-
A Coordinate-Oblivious Index for High-Dimensional Distance Similarity Searches on the GPU
Authors: Brian Donnelly and Mike Gowanlock
Paper: ICS2020
Link: https://github.com/bwd29/Coordinate-Oblivious-Similarity-Search -
Hybrid CPU/GPU Distance Similarity Self-Join for Low-dimensional Data
Authors: Benoit Gallet and Mike Gowanlock
Papers: DASFAA2020, & DSE Journal 2020
Link: https://github.com/benoitgallet/HEGJoin -
Hybrid CPU/GPU Clustering in Shared Memory on the Billion Point Scale
Authors: Mike Gowanlock
Paper: ICS2019
Link: https://github.com/mgowanlock/BPS-HDBSCAN/ -
GPU-Accelerated Distance Similarity Self-Join for Low and High Dimensional Data
Authors: Mike Gowanlock and Ben Karsin
Paper: DaMoN2019
Link: https://github.com/mgowanlock/gpu_self_join -
Hybrid CPU/GPU K-Nearest Neighbor Self-Join
Authors: Mike Gowanlock
Papers: GPGPU2019 & JPDC 2021
Note: This is the GPU component of the hybrid CPU+GPU algorithm. See the repository for details.
Link: https://github.com/mgowanlock/hybrid_k_nearest_neighbor_self_join